## Remote package repositoriessrc/gzopenwrt_corehttps://mirrors.tuna.tsinghua.edu.cn/openwrt/releases/24.10.5/targets/x86/64/packagessrc/gzopenwrt_basehttps://mirrors.tuna.tsinghua.edu.cn/openwrt/releases/24.10.5/packages/x86_64/basesrc/gzopenwrt_kmodshttps://mirrors.tuna.tsinghua.edu.cn/openwrt/releases/24.10.5/targets/x86/64/kmods/6.6.119-1-484466e2719a743506c36b4bb2103582src/gzopenwrt_lucihttps://mirrors.tuna.tsinghua.edu.cn/openwrt/releases/24.10.5/packages/x86_64/lucisrc/gzopenwrt_packageshttps://mirrors.tuna.tsinghua.edu.cn/openwrt/releases/24.10.5/packages/x86_64/packagessrc/gzopenwrt_routinghttps://mirrors.tuna.tsinghua.edu.cn/openwrt/releases/24.10.5/packages/x86_64/routingsrc/gzopenwrt_telephonyhttps://mirrors.tuna.tsinghua.edu.cn/openwrt/releases/24.10.5/packages/x86_64/telephony# passwall2src/gzpasswall_lucihttps://master.dl.sourceforge.net/project/openwrt-passwall-build/releases/packages-24.10/x86_64/passwall_lucisrc/gzpasswall_packageshttps://master.dl.sourceforge.net/project/openwrt-passwall-build/releases/packages-24.10/x86_64/passwall_packagessrc/gzpasswall2https://master.dl.sourceforge.net/project/openwrt-passwall-build/releases/packages-24.10/x86_64/passwall2## This is the local package repository, do not remove!srcimagebuilderfile:packages#option check_signature
Working with multiple GitHub accounts on the same machine can be tricky, but we can automate account switching when changing workspaces. Here’s my solution using Fish Shell and Direnv.
Prerequisites
Install direnv, this handy tool automatically loads environment variables when you cd into directories.
The Setup
Add this function to your Fish Shell configuration:
function __gh_auth_switch_gh_account --on-variable GH_ACCOUNTiftest -n "$GH_ACCOUNT"gh auth switch --user "$GH_ACCOUNT"endend
How it works
Let’s break down the snippet:
--on-variable tells Fish Shell to run this function when the variable GH_ACCOUNT changes value.
test -n $GH_ACCOUNT returns true if the length of GH_ACCOUNT is non-zero.
gh auth switch --user "$GH_ACCOUNT" switches the active account to $GH_ACCOUNT.
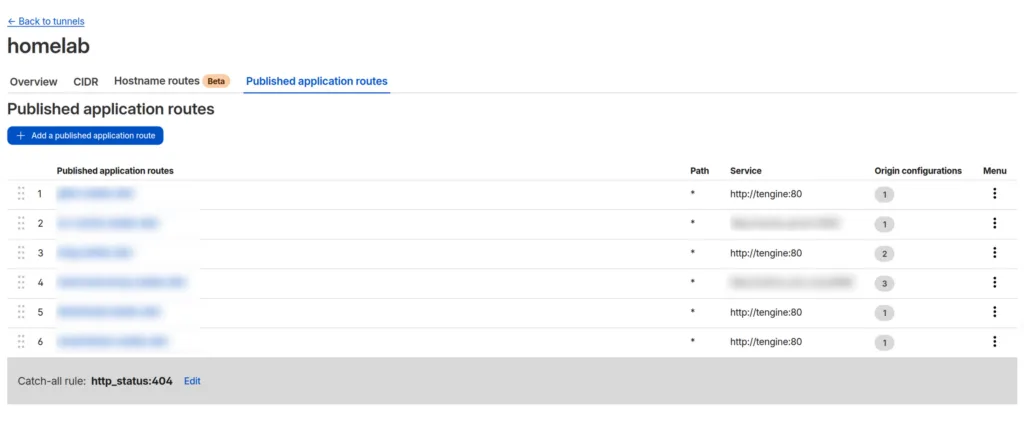
For example, if we need to switch to gh-user-1 under path/to/company/ . We can add a .envrc file under path/to/company:
export GH_ACCOUNT=gh-user-1
When we cd into path/to/company/project1, direnv will set the GH_ACCOUNT variable automatically, and the callback function __gh_auth_switch_gh_account will be invoked by the Fish Shell to make gh-user-1 active.
Aug 27 09:04:52 arch kernel: atkbd serio0: Failed to deactivate keyboard on isa0060/serio0Aug 27 09:04:52 zarch kernel: atkbd serio0: Failed to enable keyboard on isa0060/serio0
根据 Claude 以及互联网上相关的讨论,这个问题大概率跟内置键盘的驱动有关,通常可以通过尝试不同的 i8042/atkbd 相关参数来解决。
已经记不得从什么时候开始,我的 Linux 桌面偶尔会遇到无响应的问题,这个问题经常跟比较重的磁盘读写相关,例如更新 JetBrains IDE,JetBrains IDE 创建索引。之所以会把无响应的问题归结到磁盘读写上,是因为卡顿往往跟内存占用、CPU 使用率、进程数无关。卡顿的表现为:鼠标可以移动,但是 KDE 桌面包括状态栏无法更新;Kitty 可以创建新的 Tab,但是 Fish 启动会卡住;已有终端下虽然可以流畅输入命令,但是执行命令会卡住。这个周末因为成都一直在下雨,不太方便出门,决定来尝试解决卡顿问题。
我的电脑配置如下:
出现问题的固态硬盘型号是 KINGSTON SNVS1000G, SMART 信息如下:
# nvme smart-log /dev/nvme1Smart Log for NVME device:nvme1 namespace-id:ffffffffcritical_warning : 0temperature : 89 °F (305 K)available_spare : 100%available_spare_threshold : 10%percentage_used : 31%endurance group critical warning summary: 0Data Units Read : 61665672 (31.57 TB)Data Units Written : 171536497 (87.83 TB)host_read_commands : 967548759host_write_commands : 2052988968controller_busy_time : 75703power_cycles : 79989power_on_hours : 15798unsafe_shutdowns : 241media_errors : 0num_err_log_entries : 0Warning Temperature Time : 0Critical Composite Temperature Time : 0Thermal Management T1 Trans Count : 0Thermal Management T2 Trans Count : 0Thermal Management T1 Total Time : 0Thermal Management T2 Total Time : 0
然而在调度器的选择上,Gemini 跟 Arch Wiki 出现了分歧,Gemini 认为 NVME 以及 SSD 就应该选择 none 作为 io scheduler,但 Arch Wiki 认为 it depends:
The best choice of scheduler depends on both the device and the exact nature of the workload. Also, the throughput in MB/s is not the only measure of performance: deadline or fairness deteriorate the overall throughput but may improve system responsiveness. Benchmarking may be useful to indicate each I/O scheduler performance.