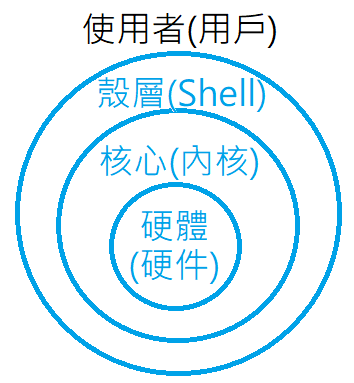
List all captured core dumps:coredumpctlList captured core dumps for a program:coredumpctl list programShow information about the core dumps matching a program with `PID`:coredumpctl info PIDInvoke debugger using the last core dump:coredumpctl debugInvoke debugger using the last core dump of a program:coredumpctl debug programExtract the last core dump of a program to a file:coredumpctl --output path/to/file dump programSkip debuginfod and pagination prompts and then print the backtrace when using `gdb`:coredumpctl debug --debugger-arguments "-iex 'set debuginfod enabled on' -iex 'set pagination off' -ex bt"
下面的这份 CMake 文件是我跟 Claude 一起编写的,不一定能够通过 IDE 编译 node addon,但是可以提供智能补全。
cmake_minimum_required(VERSION 3.10)project(duckdb_node_neo)set(CMAKE_CXX_STANDARD 17)# include node headersinclude_directories(/usr/include/node)# Node.js addon API headersinclude_directories(${CMAKE_SOURCE_DIR}/bindings/node_modules/node-addon-api)# DuckDB headersinclude_directories(${CMAKE_SOURCE_DIR}/bindings/libduckdb)# Add source filesfile(GLOB SOURCE_FILES"bindings/src/*.cpp")# This is just for CLion's code intelligence - not for actual buildingadd_library(duckdb_node_bindings SHARED ${SOURCE_FILES})# Define preprocessor macros used in the codeadd_definitions(-DNODE_ADDON_API_DISABLE_DEPRECATED)add_definitions(-DNODE_ADDON_API_REQUIRE_BASIC_FINALIZERS)add_definitions(-DNODE_API_NO_EXTERNAL_BUFFERS_ALLOWED)# Add Node.js specific definitions to help CLion's IntelliSenseadd_definitions(-DNAPI_VERSION=8)# Tell CLion to treat this as a Node.js addon projectset_target_properties(duckdb_node_bindings PROPERTIES CXX_STANDARD 17 PREFIX "" SUFFIX ".node")
生成带有 symbol 的二进制
设置后 debugger 后,还需要提供一个 symbol 文件,帮助 debugger 定位代码位置。对于 node-gyp 而言,只需要在编译时设置 --debug 参数即可生成带有 symbol 的二进制。
classMyClass{publicupdate(){}publicfooBehavior(){}publicchangeState(params){// do somethingthis.fooBehavior();// finallythis.update();}}
现在,我需要允许调用方修改 changeState 要执行的行为
classMyClass{publicupdate(){}publicfooBehavior(){}publicchangeState(params,behaviorType?:string){// do somethingif (behaviorType==='A') {// do behavior A}elseif (behaviorType==='B') {// do behavior B}else{this.fooBehavior();}// finallythis.update();}}
classMyClass{publicupdate(){}publicfooBehavior(){}publicchangeState(params,changeStateHook:ChangeStateHook=newChangeStateHook()){// do somethingchangeStateHook.after(this);// finallythis.update();}}classChangeStateHook{after(instance:MyClass){instance.fooBehabior();}}classConsumerChangeStateHookextendsChangeStateHook{after(instance:MyClass){if(/* some case */) {super.after();}else{// do something else}}}